 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextWorldExpress: Simulating Text Games at One Million Steps Per Second
Aug 01, 2022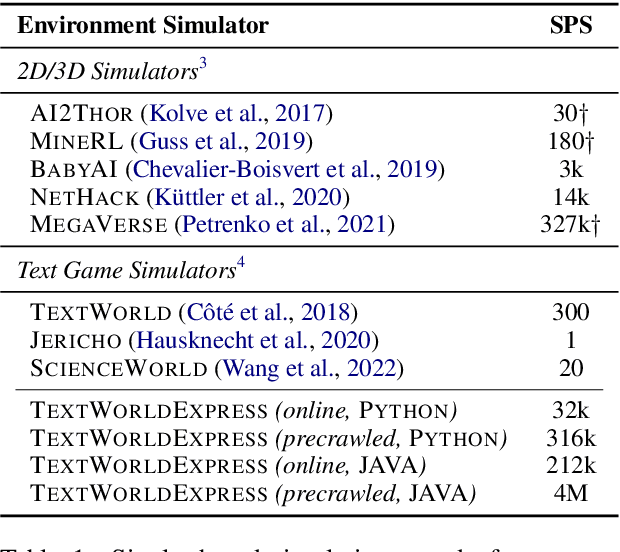


Text-based games offer a challenging test bed to evaluate virtual agents at language understanding, multi-step problem-solving, and common-sense reasoning. However, speed is a major limitation of current text-based games, capping at 300 steps per second, mainly due to the use of legacy tooling. In this work we present TextWorldExpress, a high-performance implementation of three common text game benchmarks that increases simulation throughput by approximately three orders of magnitude, reaching over one million steps per second on common desktop hardware. This significantly reduces experiment runtime, enabling billion-step-scale experiments in about one day.
Visually-Grounded Planning without Vision: Language Models Infer Detailed Plans from High-level Instructions
Oct 26, 2020
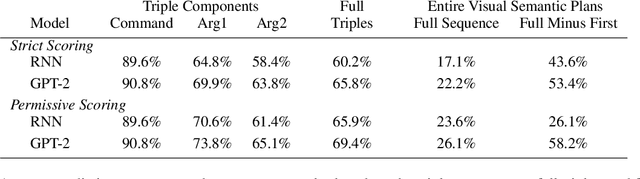
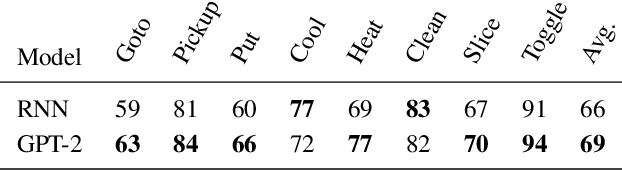
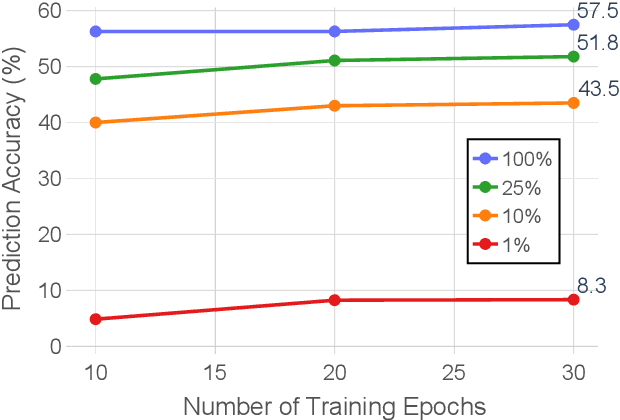
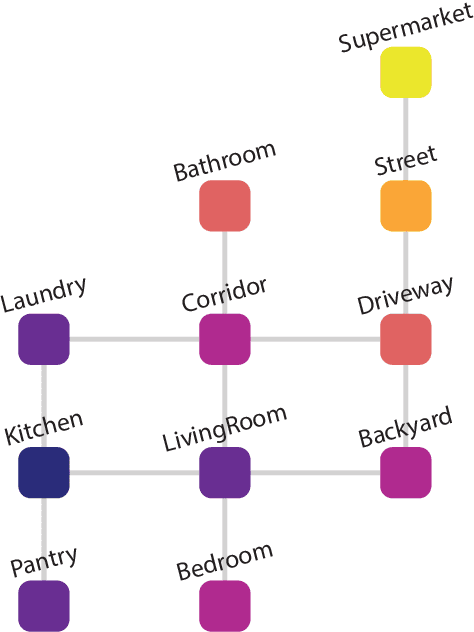
The recently proposed ALFRED challenge task aims for a virtual robotic agent to complete complex multi-step everyday tasks in a virtual home environment from high-level natural language directives, such as "put a hot piece of bread on a plate". Currently, the best-performing models are able to complete less than 5% of these tasks successfully. In this work we focus on modeling the translation problem of converting natural language directives into detailed multi-step sequences of actions that accomplish those goals in the virtual environment. We empirically demonstrate that it is possible to generate gold multi-step plans from language directives alone without any visual input in 26% of unseen cases. When a small amount of visual information is incorporated, namely the starting location in the virtual environment, our best-performing GPT-2 model successfully generates gold command sequences in 58% of cases. Our results suggest that contextualized language models may provide strong visual semantic planning modules for grounded virtual agents.
WorldTree: A Corpus of Explanation Graphs for Elementary Science Questions supporting Multi-Hop Inference
Feb 08, 2018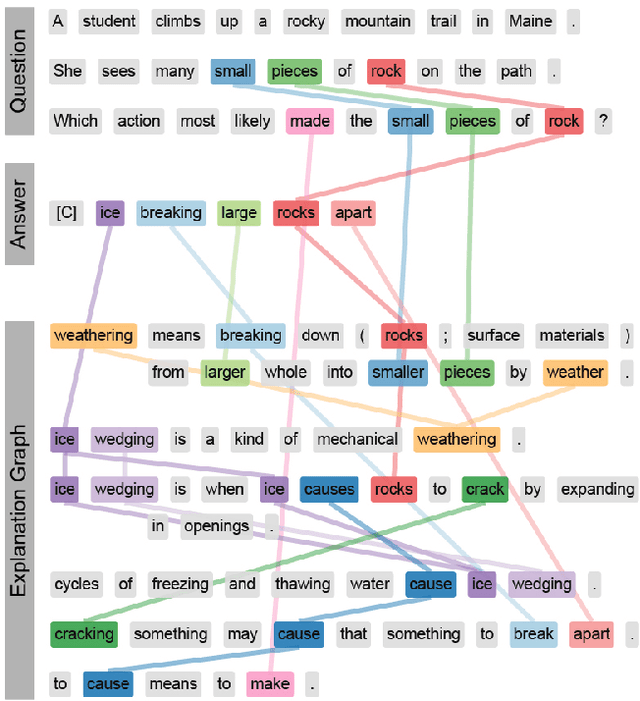
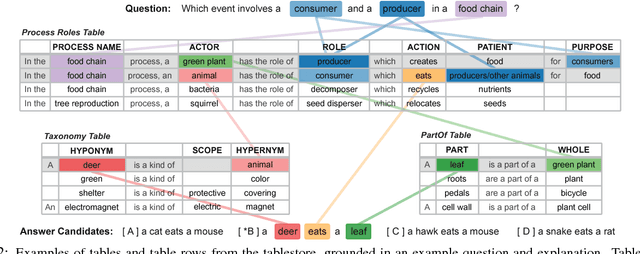

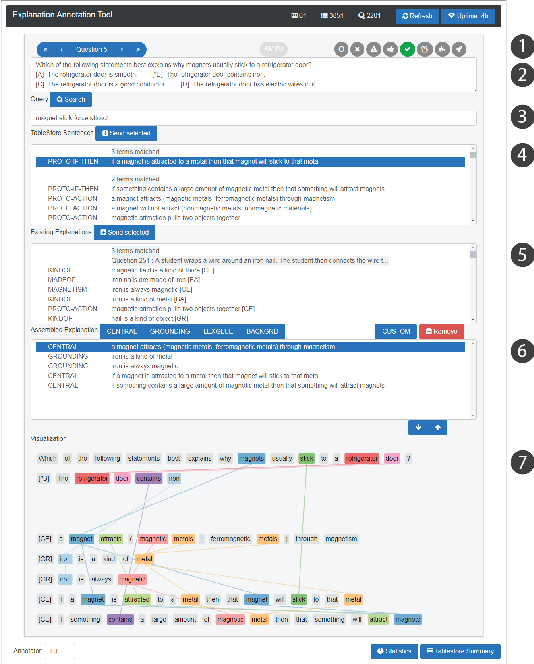
Developing methods of automated inference that are able to provide users with compelling human-readable justifications for why the answer to a question is correct is critical for domains such as science and medicine, where user trust and detecting costly errors are limiting factors to adoption. One of the central barriers to training question answering models on explainable inference tasks is the lack of gold explanations to serve as training data. In this paper we present a corpus of explanations for standardized science exams, a recent challenge task for question answering. We manually construct a corpus of detailed explanations for nearly all publicly available standardized elementary science question (approximately 1,680 3rd through 5th grade questions) and represent these as "explanation graphs" -- sets of lexically overlapping sentences that describe how to arrive at the correct answer to a question through a combination of domain and world knowledge. We also provide an explanation-centered tablestore, a collection of semi-structured tables that contain the knowledge to construct these elementary science explanations. Together, these two knowledge resources map out a substantial portion of the knowledge required for answering and explaining elementary science exams, and provide both structured and free-text training data for the explainable inference task.